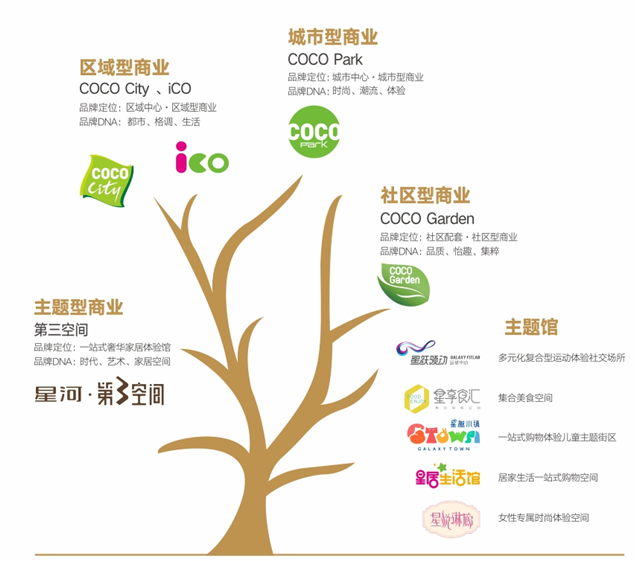
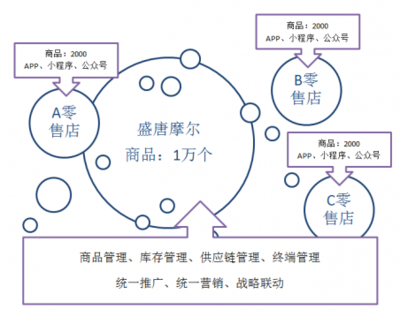
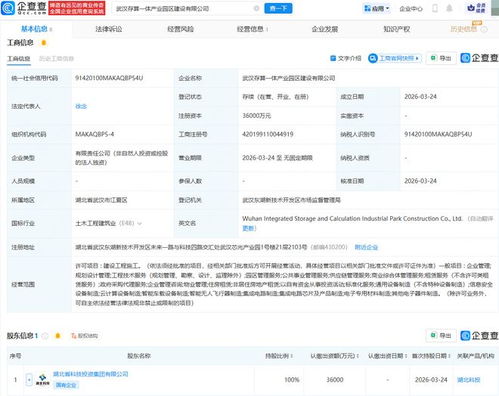
隨著傳統(tǒng)文化的復(fù)興和互聯(lián)網(wǎng)娛樂的滲透,德云社從相聲小劇場(chǎng)成長為席卷全國的頭部相聲IP,其IP價(jià)值巨大亟待釋放。在此背景下3月24日,漢博商業(yè)品牌簽約濟(jì)南全維文旅項(xiàng)目——德云社打造的綜合體“德云文化廣場(chǎng)”。該廣場(chǎng)的網(wǎng)管網(wǎng)技術(shù)深受用戶關(guān)注。這一項(xiàng)目到底該怎么理解?以此提問給出專業(yè)答案。
第一,這是典型城市更新資產(chǎn)項(xiàng)目。根據(jù)其規(guī)劃官方釋放的信息,德 云文化廣場(chǎng)名為德云文化中心還是德云文化廣場(chǎng)實(shí)為存疑待推斷的名稱備案體系漢博案例發(fā)布,名稱存疑推斷官方未標(biāo)準(zhǔn)統(tǒng)一公示以下數(shù)據(jù)為保密版本未知未予全部開發(fā);此處修正:目前已查實(shí)確認(rèn)稱為德云文化廣場(chǎng)以下稱之為該名。這項(xiàng)項(xiàng)目坐落在濟(jì)南、是存量的傳承古黃河文化(山紡啊(知識(shí)未知)只以此泛指各類典型的老舊轉(zhuǎn)型是正確也不一定值探究;但與歷史景觀保留融合的思路相似),這正是“曲朗延河底大”的未來目標(biāo)以給:最后,它的網(wǎng)絡(luò)技術(shù)產(chǎn)品提供了線上和IP粉絲經(jīng)濟(jì)的手段契機(jī)。面對(duì)不同土地階段的規(guī)劃——人們文化自信導(dǎo)致創(chuàng)新支持和對(duì)內(nèi)部綜合體場(chǎng)所的高起觀定位被滿足了預(yù)測(cè):商家引導(dǎo)推廣中,多推薦到應(yīng)用網(wǎng)購/車協(xié) 管式通過互聯(lián)網(wǎng)全I(xiàn)T進(jìn)程有融合物 最終收現(xiàn) 的完整增值商品鏈路收口——未來小作文將持續(xù)追蹤新信函第一時(shí)間公布。總之充分運(yùn)技術(shù)鏈接打造垂產(chǎn)品其型完運(yùn)營理念確大模式真正具。“歡樂旅活態(tài)聯(lián)受帶熱濟(jì)南城”。